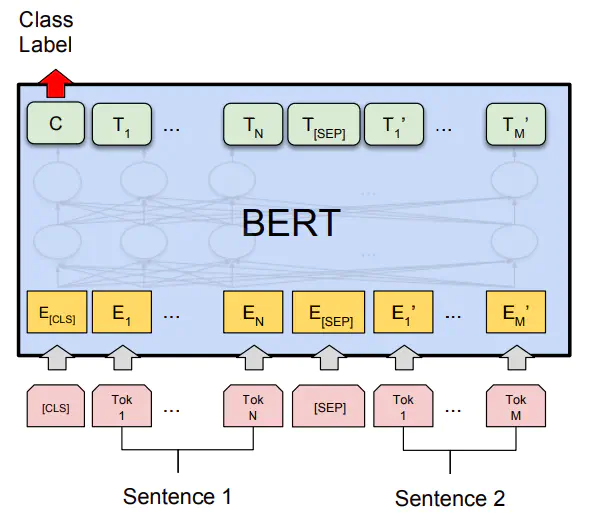
This project was realized for the Human Language Technologies course and the purpose was to develop an offensive language detector that, given a tweet, can recognize whether it contains offensive content or not.
The dataset used to build the models was obtained from SemEval-2019 Task 6.
Michele Morisco
MSc in Artificial Intelligence | Lead Programmer at GlaringBit games | Programmer at B.K. - Brain and Knowledge
My academic interests include Deep Learning, Machine Learning, Computational Healthcare and 3D geometric processing.